 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedbackSTS-Det: Sparse Frames-Based Spatio-Temporal Semantic Feedback Network for Infrared Small Target Detection
Jan 21, 2026Infrared small target detection (ISTD) under complex backgrounds remains a critical yet challenging task, primarily due to the extremely low signal-to-clutter ratio, persistent dynamic interference, and the lack of distinct target features. While multi-frame detection methods leverages temporal cues to improve upon single-frame approaches, existing methods still struggle with inefficient long-range dependency modeling and insufficient robustness. To overcome these issues, we propose a novel scheme for ISTD, realized through a sparse frames-based spatio-temporal semantic feedback network named FeedbackSTS-Det. The core of our approach is a novel spatio-temporal semantic feedback strategy with a closed-loop semantic association mechanism, which consists of paired forward and backward refinement modules that work cooperatively across the encoder and decoder. Moreover, both modules incorporate an embedded sparse semantic module (SSM), which performs structured sparse temporal modeling to capture long-range dependencies with low computational cost. This integrated design facilitates robust implicit inter-frame registration and continuous semantic refinement, effectively suppressing false alarms. Furthermore, our overall procedure maintains a consistent training-inference pipeline, which ensures reliable performance transfer and increases model robustness. Extensive experiments on multiple benchmark datasets confirm the effectiveness of FeedbackSTS-Det. Code and models are available at: https://github.com/IDIP-Lab/FeedbackSTS-Det.
To Compress, or Not to Compress: Characterizing Deep Learning Model Compression for Embedded Inference
Oct 21, 2018
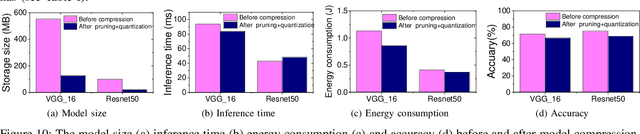

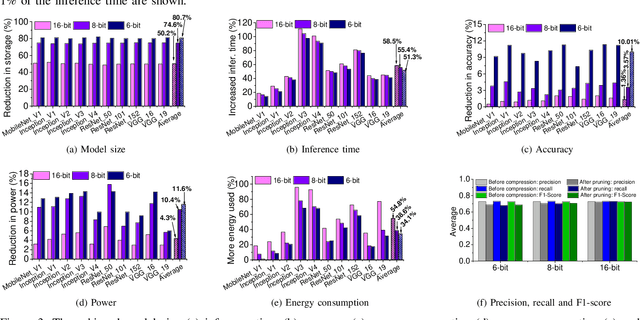
The recent advances in deep neural networks (DNNs) make them attractive for embedded systems. However, it can take a long time for DNNs to make an inference on resource-constrained computing devices. Model compression techniques can address the computation issue of deep inference on embedded devices. This technique is highly attractive, as it does not rely on specialized hardware, or computation-offloading that is often infeasible due to privacy concerns or high latency. However, it remains unclear how model compression techniques perform across a wide range of DNNs. To design efficient embedded deep learning solutions, we need to understand their behaviors. This work develops a quantitative approach to characterize model compression techniques on a representative embedded deep learning architecture, the NVIDIA Jetson Tx2. We perform extensive experiments by considering 11 influential neural network architectures from the image classification and the natural language processing domains. We experimentally show that how two mainstream compression techniques, data quantization and pruning, perform on these network architectures and the implications of compression techniques to the model storage size, inference time, energy consumption and performance metrics. We demonstrate that there are opportunities to achieve fast deep inference on embedded systems, but one must carefully choose the compression settings. Our results provide insights on when and how to apply model compression techniques and guidelines for designing efficient embedded deep learning systems.